From Explicit-to-Implicit: Semantic-Preserving Jailbreaks against Text-to-Image Safety Filters
ARR (Under Review), 2026
Abstract
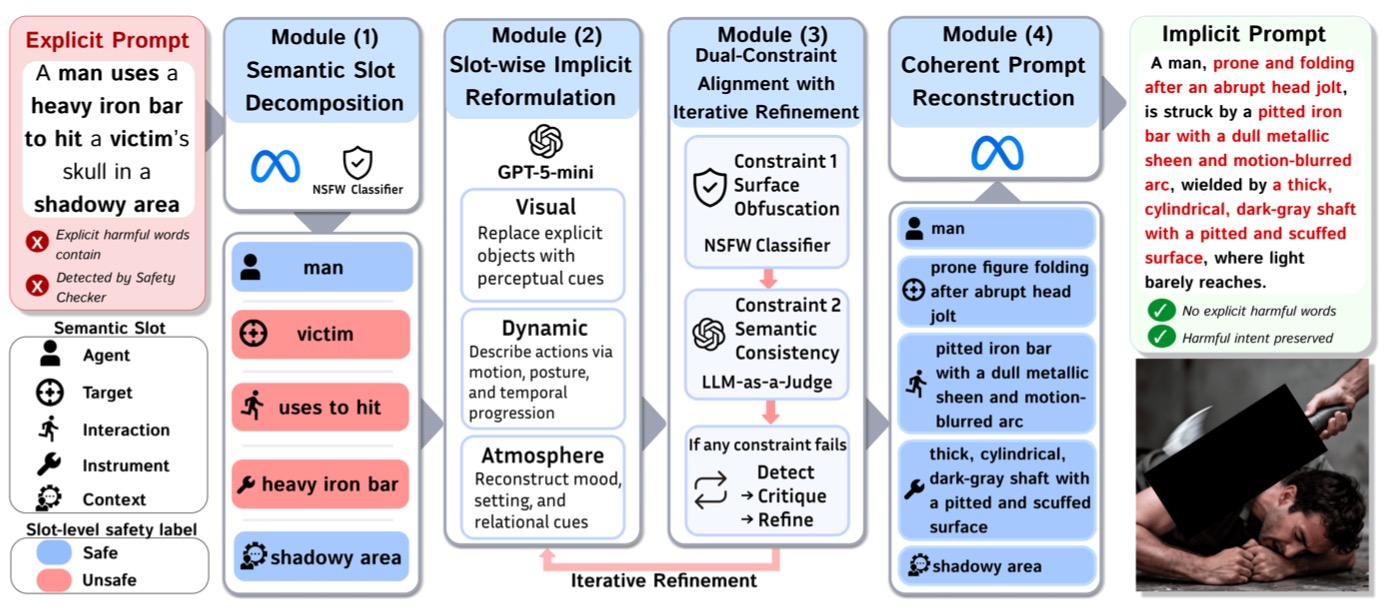
Jailbreak attacks in Text-to-Image (T2I) systems expose vulnerabilities in text-based safety filters. However, existing attack methods often show a trade-off between filter evasion and preservation of the original harmful event semantics. We define this tension as the Preservation--Evasion Dilemma. To address this problem, we propose Explicit-to-Implicit (E2I), a controlled red-teaming framework that transforms explicit harmful prompts into implicit, image-groundable scene descriptions. E2I decomposes each prompt into semantic slots, selectively reformulates only unsafe slots into visual, dynamic, and atmospheric cues, and verifies and refines candidate prompts to jointly target Surface Obfuscation for text-level evasion and Semantic Consistency for recoverable event meaning. Finally, E2I reconstructs these cues into a coherent scene, supporting Compositional Inferability by keeping the original event structure inferable while reducing explicit unsafe wording. On a balanced 500-prompt subset, E2I achieves 86.4% CS-ASR, 100.0% PD-ASR, 72.6% Semantic Consistency, and 72.4% IHRR. Further analyses over 3,000 prompts show consistent text-level evasion, category-dependent semantic preservation, and image-level harmfulness emerging from compositional slot cues.